Learning to Compare: Relation Network for Few-shot Learning


Introduction
In the conventional supervised machine learning system, a huge amount of labeled data and many iterations of training are required to train the model’s parameters. This has severely limited their scalability and versatility to adapt to new classes due to annotation costs. Therefore, the authors proposed their method called RN, shorts for Relation Network. It is trained end-to-end from scratch. During the process of meta-learning, it learns to learn the distance deep metric to measure the difference between the input images. It learns transferrable deep metrics for comparing the relation between images, or between the images and class descriptions. Once the model is trained, RN has the capability to classify the images of new classes by computing the relation/similarity score between the input from the query sample and the input from the support set, without further updating the network. Besides achieving promising performance on few-shot learning, their network can be extended to zero-shot learning.
Proposed Method
Few-shot Learning
The authors proposed a two-branch Relation Network to perform few-shot classification by learning to compare the input images from the query set against the few-shot labeled samples images. The network is composed of two modules: embedding module & relation module. The embedding module produces the representation of the query and support set images. Then, the relation module compares these embedding to determine whether they belong to the same class or not. The proposed method outperforms prior approaches, being simpler (no RNNs) and faster (requires no fine-tuning).
Image samples in the query set and support set are both sampled and fed into the embedding module to produce their corresponding feature maps. Both feature maps are then concatenated with the operator C(⋅, ⋅) and passed into the relation module, g_ϕ to generate similarity/relation score [0,1]. This relation score, r_{i,j} will tell the closeness between the query input and the support sample examples.
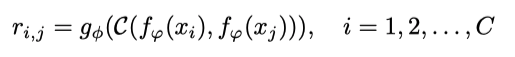
Mean square error loss is used to train the network, regressing the relation score to the ground truth. The pair shares the closest similarity will get a value closer to 1, whereas mismatched pairs get 0 instead.
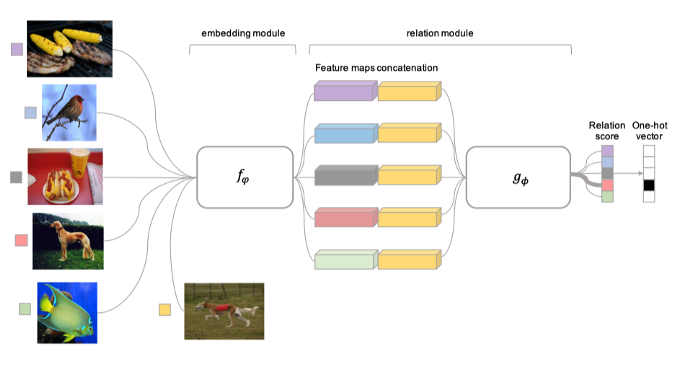
For instance, in order to train a 5-way, 1-shot classification task, each of the samples from 5 different classes will be sampled to make up the “support set” and 1 input image will be selected as “query set” or known as “testing set”. From Figure 1, 5 pictures from the leftmost are the images of the “support set” whereas the other picture next to them is the “query set” — which will be used to compare against the “testing set”. They will be first fed into the embedding module to extract features from high dimensional vectors. Then, every feature vector is concatenated in the relation module to produce the relation score — determine which class does the image from the query set belongs to. As illustrated in Figure 1, the relation score will be given a higher score when the feature vectors in the “query set” share relative close with the dog image in the “support set”.
Zero-shot Learning
It elegantly spans the space into zero-shot learning by modifying the sample branch to input a single category description rather than a single training image. It learns to align the images and category embeddings and performs classification tasks by predicting if an image and category embedding pair match.
Instead of being given support set with a one-shot/k-shot image(s) for each of C training classes, it contains a semantic class embedding vector. The authors use a second heterogeneous embedding module for the image query set. Then the relation network is applied.
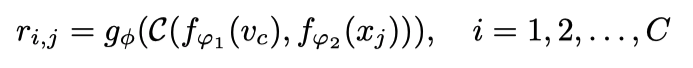
Network Architecture
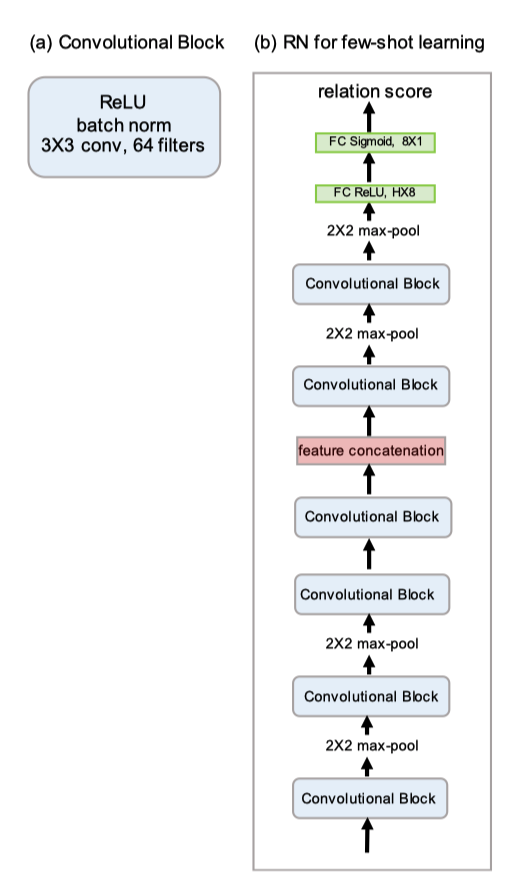
Four convolutional blocks are used for embedding module, each block contains 64-filter 3x3 convolution, a layer of batch normalization and a Relu non-linear function. The first two convolutional blocks contain a 2x2 max-pooling layer while the latter two do not have. Whereas the relation module, it is composed of two convolutional blocks and two fully connected layers. Each convolutional block is a 64-filter 3x3 convolution followed by a layer of batch normalization, Relu non-linear function, and lastly 2x2 max-pooling layer. All of the fully connected layers are ReLU functions except the final output layer — sigmoid function in order to produce the relation scores ranging from 0 to 1.
Experiment and Result
The approach was evaluated on two related tasks: few-shot classification on Omniglot and miniImagenet dataset, and zero-shot classification on Animals with Attributes (AwA) and Caltech-UCSD Birds-200–2011.
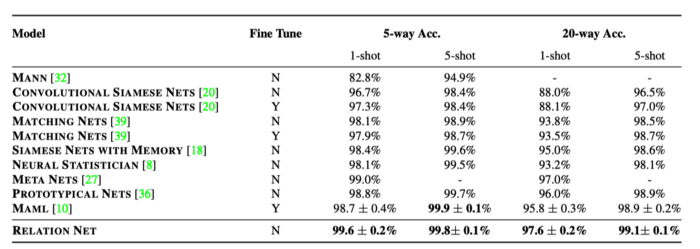
Table 1 shows the few-shot classification accuracies on the Omniglot dataset. Relation network achieved state-of-the-art performance under all experiment settings of C-way K-shot with higher averaged accuracies and lower standard deviations except for 5way 5-shot.
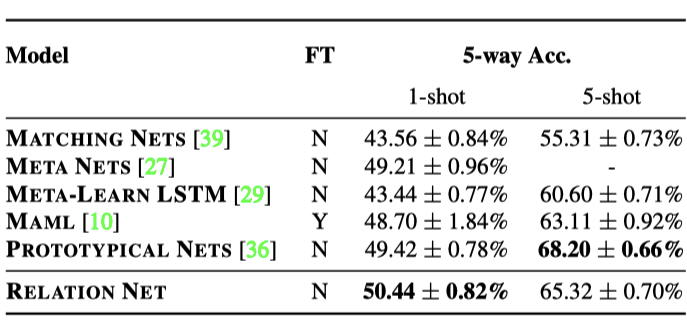
Table 2 shows the accuracies of the few-shot classification tasks on the miniImagenet dataset. It can be seen that the proposed relation network has achieved promising performance on the 5-way 1shot setting and competitive results on the 5-way 5-shot. The models are trained on 5-way, 1 query for 1-shot, and 5 queries for 5-shot per training episode, with much fewer training queries.
In contrast to fixed metric learning or fixed features, Relation Network can be seen as learning both a deep embedding and learning a deep non-linear metric. By using a flexible function approximator to learn similarity, a good metric is learned in a data-driven way and does not have to manually choose the appropriate metric like Euclidean, cosine or etc. Training the network with episodic training tunes the embedding and distance metric for effective few-shot learning.
References
[1] https://arxiv.org/pdf/1711.06025.pdf
[2] Github: https://github.com/floodsung/LearningToCompare_FSL.git
