Object-Level Representation Learning for Few-Shot Image Classification


Introduction
Human exhibits a strong ability to understand concepts quickly in real life. We can perceive and recognize the variation of the objects easily based on prior knowledge, deductive reasoning. Therefore, we are trying to transfer this idea and get them implemented on the machine learning system. However, conventional machine learning system usually requires a large amount of data and the labeling classes can be humongous, to train. Hence, the idea of few-shot learning is devised — a small number of examples of possible classes is used to train the model to do the classification task.
Methodology
The authors proposed a novel approach by learning image similarity based on their object-level relation. It is called OLFSL, abbreviate for Object-Level Few-Shot Learning. The objects from the two images are compared to learn the object level relation — to infer the similarity of the objects. This model comprises 3 main parts: representation learning 𝔉ϕ(x), object relation learning ℜθ(a,b), and similarity learning 𝔖ϕ(r).
The representation learning extracts the features of the objects from each input image. These features will then be fed into the object relation learning module and generate an image-level similarity score. The nearest neighbor search is subsequently applied over the target dataset to do a few-shot classification.
It exploits the object-level relation learned from known categories to infer the similarity of the samples from unseen classes. The approach is evaluated against two datasets — Omniglot and MiniImagenet dataset.
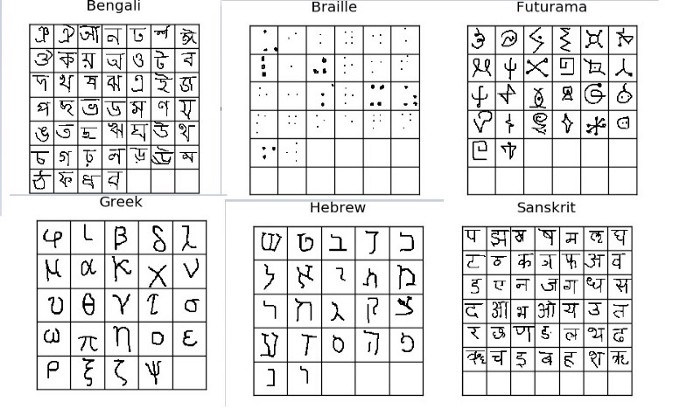
Omniglot Dataset
It uses the Omniglot dataset, which comprises 1623 hand-drawn characters from 50 different alphabets ( each drawn by a different person ). Each of the images is a grayscale image with 105x105 dimensions.
For clarification on the difference between character and alphabet — take English as an example, from A-Z is considered as the alphabet whereas each of the letters A, B … Z is known as character. Therefore, the English alphabet has 26 characters.
The Omniglot dataset can be downloaded here.
MiniImageNet Dataset
This dataset was proposed by Ravi & Larochelle[1]. It consists of 100 classes with 600 samples of 84x84 color images per class. The MiniImageNet dataset is available to download by clicking here.
Model Architecture
In the process of few-shot learning, the model is fed with a set of labeled images 𝔖 = {(x1, y1), (x2, y2), … , (xn,yn)}, where x denotes the feature of an image and y denotes the class label. It is very common to see the term N-way K-shot learning, where N means the number of image examples per class and K means the number of class labels.
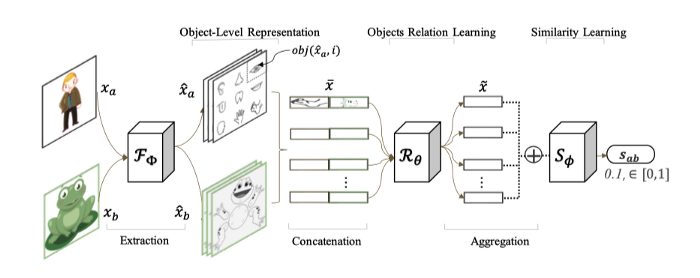
From the illustration above, xα is denoted as the feature of a raw image, and yα is denoted as its label. They are fed into the convolution neural network to extract useful features from high-dimensional space. Subsequently, the object level relation learning compares the vector representation of these two inputs, by concatenating objects pair-wisely.
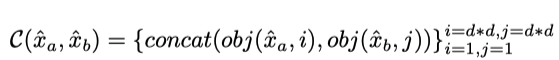
Each of the concatenated vectors is then supplied to a fully connected neural network to learn the object-level relation. All object relation vectors are aggregated to form image-level relations.
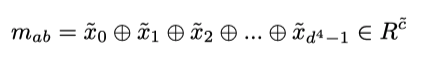
Then it feeds the image level relation feature vector to the fully connected neural network to compute the similarity score. It is used to calculate the similarity between vector α and vector β and finally normalized to [0,1] where 0 denotes they both belong to different classes and 1 denotes the same class.
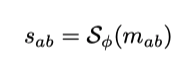
The algorithm for object-level few-shot learning is shown below.

Experiment and Result
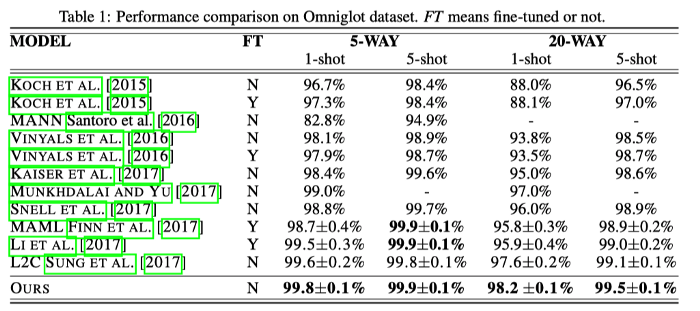
The experiment settings on the Omniglot dataset are done with 5-way 1-shot, 5-way 5-shot, 20-way 1-shot, and 20-way 5-shot. The result is averaged over 600 test episodes and reported with 95% confidence intervals. It can be seen that the approach outperforms existing methods for 3 out of 4 tasks.
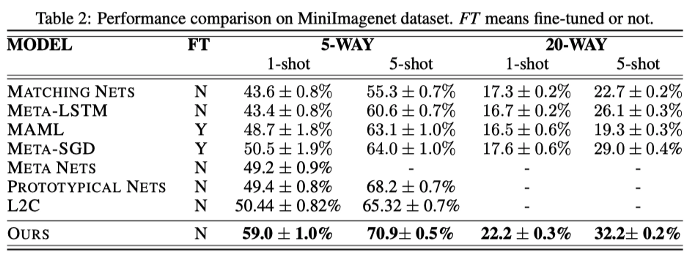
The settings of experiment on the MiniImageNet is also similar. It can be seen that also the model achieves better improvement over the existing methods.
References
a. https://arxiv.org/pdf/1805.10777
b. https://www.cs.cmu.edu/~rsalakhu/papers/oneshot1.pdf
[1] Ravi, Sachin and Larochelle, Hugo. Optimization as a model for few-shot learning. In International Conference on Learning Representations (ICLR), 2017
[2] MiniImageNet: https://drive.google.com/uc?id=0B3Irx3uQNoBMQ1FlNXJsZUdYWEE&export=download
